
Kubernetes has revolutionized the deployment and management of containerized applications, offering powerful tools to optimize resource utilization and application performance. One critical feature for efficient Kubernetes management is the Node Selector, a powerful yet straightforward mechanism for controlling pod placement across cluster nodes. Understanding how to use node selectors effectively can significantly enhance your Kubernetes deployments’ performance, cost-efficiency, and reliability.
To simplify this technical concept, let’s use an engaging real-life analogy.
Imagine you’re managing a significant conference event with multiple rooms, each designed for specific sessions. Some rooms are equipped specifically for workshops, some for keynote speeches, and others for networking events. To efficiently organize your event, you’d ensure each session takes place in the most suitable room based on its requirements—technical workshops in rooms with projectors and whiteboards, keynote speeches in large auditoriums, and casual networking in lounges.
This scenario closely mirrors Kubernetes and how it handles pods and nodes.
What is a Node Selector?
In Kubernetes, nodes are the worker machines that run your containerized applications. Sometimes, you want certain pods to run on specific nodes due to requirements like hardware specifications, security constraints, or location. This is where a Node Selector comes in handy—it allows you to assign pods to nodes with particular labels.
How does Node Selector work in Kubernetes?
Node Selector is a straightforward mechanism in Kubernetes that allows you to ensure pods are scheduled on nodes matching specific labels. It’s essentially a way to control which pods go to which nodes.
Workflow of Node Selector
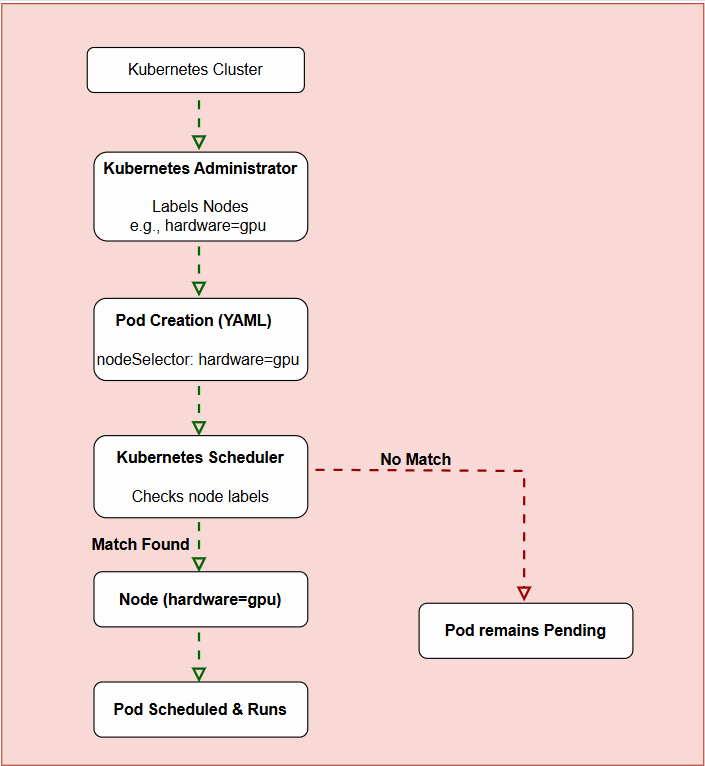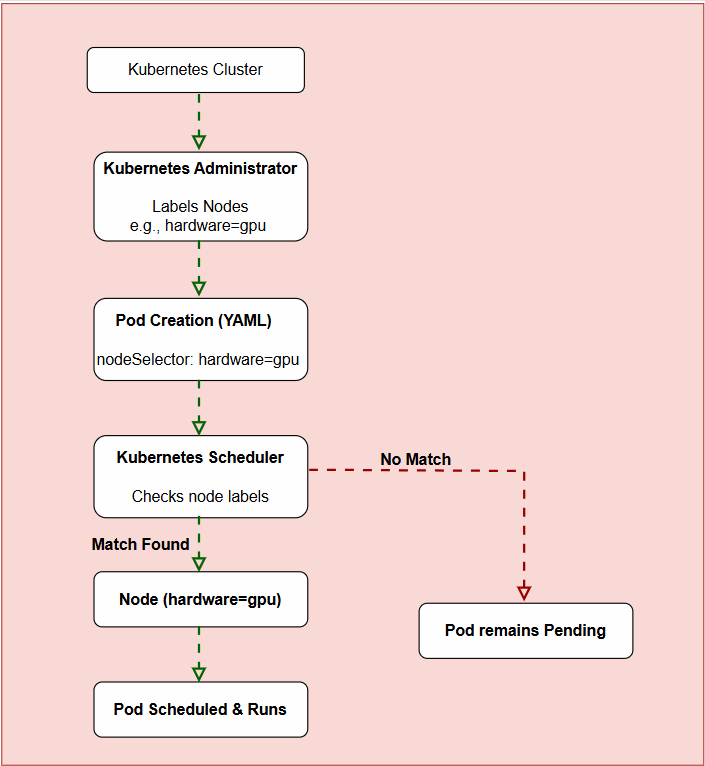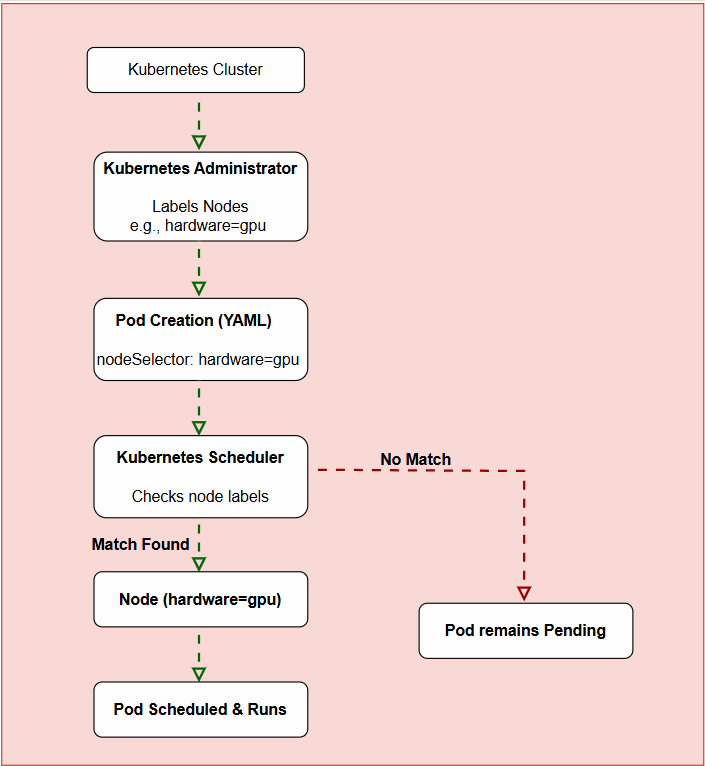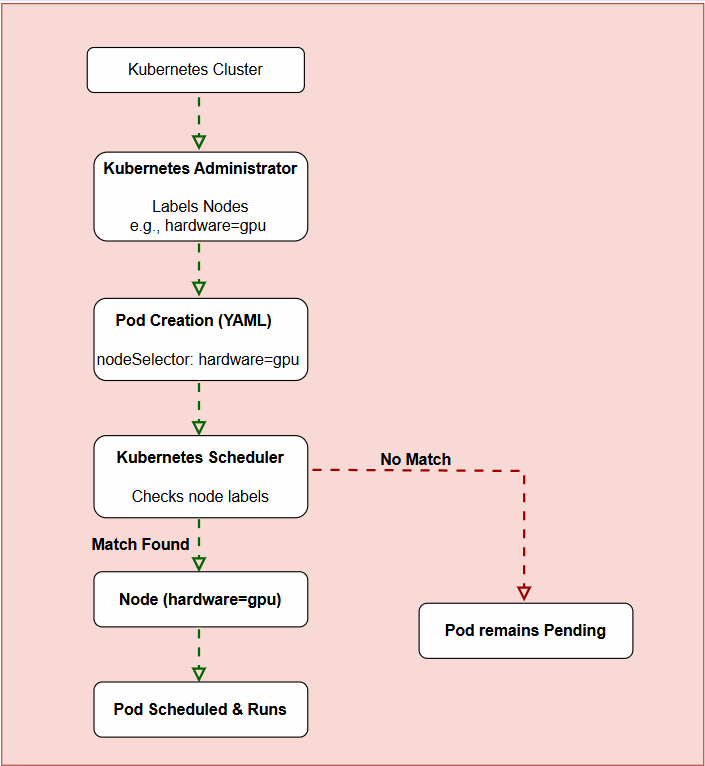
Here’s the detailed workflow describing exactly how Node Selector functions:
Step 1: Label Nodes – First, the Kubernetes administrator labels nodes based on their capabilities or intended use:
kubectl label nodes node-1 hardware=gpu
kubectl label nodes node-2 hardware=standardStep 2: Pod Creation with Node Selector – When creating a pod, you specify the nodeSelector in the pod’s YAML file, indicating the desired node label:
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: gpu-container
image: tensorflow/tensorflow:latest-gpu
resources:
limits:
nvidia.com/gpu: 1
nodeSelector:
hardware: gpuStep 3: Pod Scheduling
- The Kubernetes scheduler inspects the pod’s
nodeSelector. - It searches nodes for matching labels.
- The pod is scheduled onto a node only if the node’s labels match the pod’s
nodeSelector.
Step 4: Pod Execution
- Once matched, Kubernetes schedules the pod onto the selected node.
- The pod begins running on that node.
Step 5: No Match Found (Optional) – If no nodes match the specified label, the pod remains in the Pending state, indicating no appropriate nodes are available.
Node Selector Workflow Diagram
Here’s a simple diagram illustrating this workflow:
Benefits
- Efficient Resource Utilization: Ensures workloads run on nodes best suited to their needs.
- Cost Optimization: Avoids unnecessary resource wastage by scheduling pods appropriately.
- Improved Reliability: Ensures applications always run under the right conditions.
Like assigning sessions to the right rooms at a conference, Kubernetes Node Selectors ensure pods are deployed on appropriate nodes. By strategically using node selectors, you can optimize your Kubernetes cluster’s efficiency and reliability, making your cloud-native applications more robust and cost-effective.





